System Context Analysis & Incident Response Engine Dev Journal 1
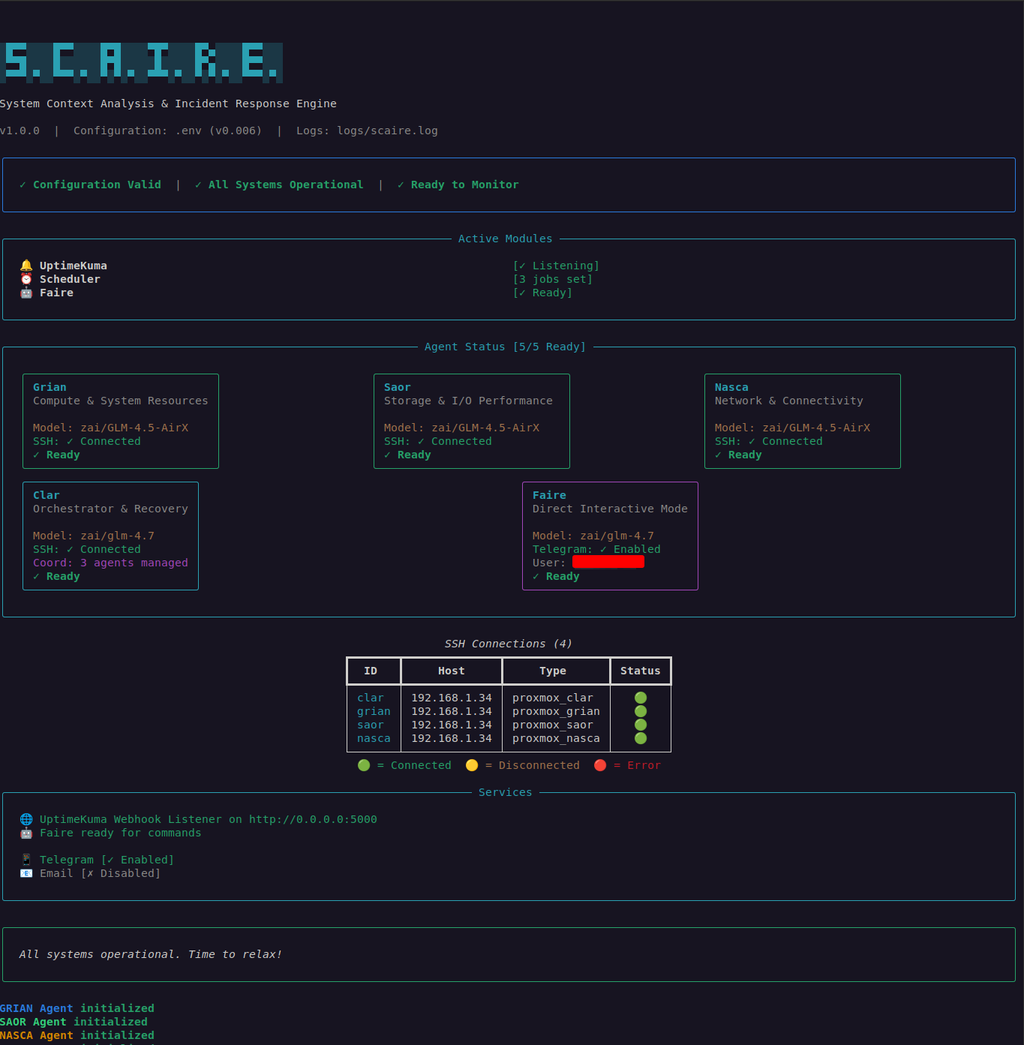
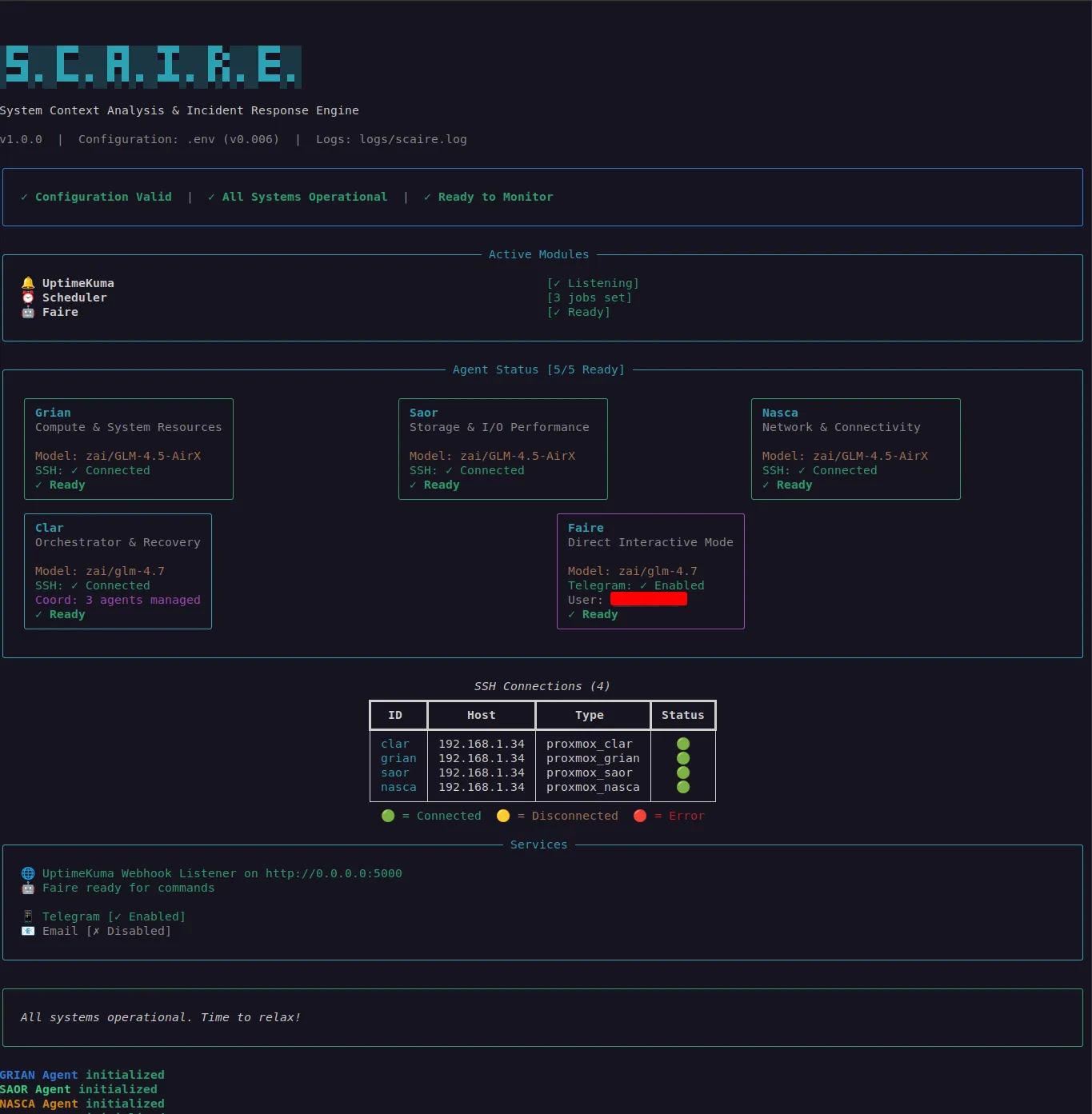
Fig. 1. S.C.A.I.R.E. CLI Screenshot
Source: Adapted from [1]
Before products began using AI Agents to control aspects of a personal computer and became more than just an idea, I was thinking about a problem that I wanted to solve back in December 2025.
The Problem: Low Resolution Notifications
Receiving notifications about problems in my environment is often too low resolution to make decisions. Sometimes it’s just a blip, sometimes it’s better to solve in the morning, but then once in a while it’s an all hands on deck situation. Then you begin getting pinged by people.
SMS: “Hey Brad, the websites down, what’s going on?”
Email Received: Ticket Subject: Someone said the services were down?
Incoming Phone Call: From someone else, while your spouse is beginning to ask more questions. “Do you need to take that?”.
Google Chat: “Hey! I think the websites down but I’m in the car right now. ~Voice Transcription by Android Auto”
There is a moment in time here where your spouse has figured out a specific look on your face, a vein has begun to form on your forehead, and you know some things to be true but you do not have the context to answer questions. Your brain begins to iterate a whirlwind of thoughts:
- Last hardware audit.
- Weird logs you noticed a month ago.
- Firewall policies and the order they are overwritten in on a fail2ban policy.
- Other misc edge cases or unknown externality?
The overall flood of recollection is often intense. You need to get connected, you need to quickly learn more. This leads to finding a quiet space and firing up whatever device you have available to make do with and whatever software capable enough to try and find those answers.
You connect, login, hammer in a few commands. How you handle yourself in the next few minutes can have long lasting personal or professional consequences. You need to respond and say something.
Alternatively, ignore the request, feign ignorance and deal with the fallout later. You’ll totally be able to focus on the other person the rest of the evening and not space out while they are bearing some deep conversation on you right?
Engineering my Way Out of this Situation
My environments have had many different tools over the years for incident response context. I’m always on the hunt for products that can give me more.
Currently my homelab has the following setup:
Watchers
Services designed to recognize when something is going wrong.
- Librenms: Analyzes and receives reports via SNMP about hardware, networking, processes with triggers to various notifiers.
- UptimeKuma: Detects if a service is down via many triggers surrounding http/https, ping, curl which all boils down to “is this service reachable”.
- Grafana, Prometheus, and Loki: Provides more insight into ongoing logging but is not necessarily providing context surrounding the issue.
There’s many more and it just comes down to your brand and comfort but these are mine.
Notifiers
Services designed to compile and deliver some sort of context about what has gone wrong.
- Gotify: Sends very quick push notifications plugs in as a notifier to all of these tools.
- Telegram: Sends similar to Gotify but offers a bit more customization for very important services via webhooks.
- Trusty email notifications: For important emergent issues.
Why so Many?
- Not every service watcher matches to every kind of service.
- Not every notifier works well with every situation.
- The existing services are all plagued by the same issue: I have to preplan expectations of exactly what might go wrong to receive additional trigger context in majority of cases.
What if Though?
What if I could go agentic first in workflow? (I know🤮 but HMB🍺)
We can have the LLM do some of this context checking for me to tackle those questions upon notification?
There was a Network Chuck video I watched about the N8N low-code platform a little while back. It stuck in my head because Chuck’s example had an LLM using an SSH tool and a root account. It was stomach churning security wise to me but that was beyond the point he was trying to make.
Thoughts continued:
- I don’t have to give the LLM every command or root access or even
/etc/access where sensitive data might live.- I could hide everything that would be considered sensitive with some clever development and a few layers of danger prevention.
- Maybe I could use the mechanisms in Linux to act as a security layer. That’s what I would do if I was training someone to be less danger to themselves. I would just tighten up the environment and put the guard rails in for them. How is this so different?
- Production ready? It doesn’t have to be for my homelab.
The “What if” was beginning to turn into a bit of an idea.
More thoughts:
- I’ll bet I can even add a second layer of protection at the program level to also banlist certain commands for dangerous interactions before they reach the server.
- We can even layer it into the LLM’s system context (brain) as another less dependable soft limit layer of protection to help avoid certain interactions. I mean, really, how many possibilities could there be?
- Still, that’s going to be a lot of testing, effort, and all of that is before even gaining any context whether something has gone wrong on my Proxmox server.
The N8N Experiment
I installed a copy of N8N and taught myself how to use the node based low-code environment. It’s interesting, has some automation use cases. The low resolution consideration is that, if you need to get text from “somewhere” then transform that text and send it “somewhere different”. Which is exactly what I was looking at for this idea.
Really it’s just move some text around right?
- Receive an UptimeKuma Webhook if something is down.
- Transform that for an LLM, pepper in some system context.
- Give the LLM some sort of means to safely execute SSH for stdout output to my Proxmox server and even somewhat independently decide which commands to send to gather that context.
- Format text output the LLM spits out properly for Telegram.
Seems straightforward plausible enough.
This screen below shows my graveyard of 37 different N8N projects all related to various components, and other supporting infrastructure that took me from “let’s play with this LLM idea” to looking like one of those YouTubers showing you a 100 point infrastructure map and trying to sell you automation tutorial snake oil. Ridiculous.
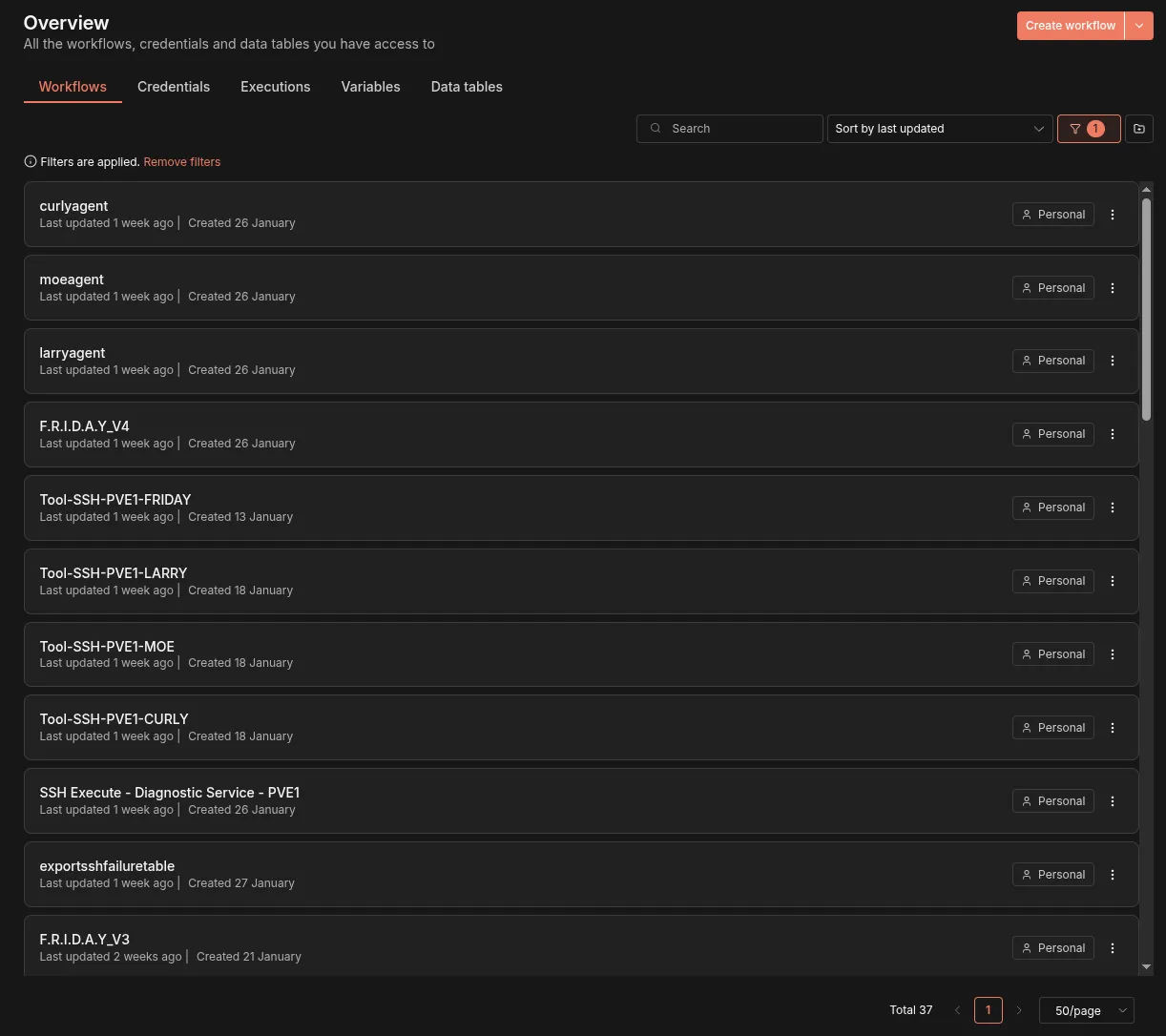
Hitting the Wall
As with most projects, from here I would go on to solve hundreds of bite sized issues but the cracks of N8N were beginning to show.
Major Barriers:
- Asynchronous LLM calls had become a pretty big barrier. For efficient LLM use I needed small effective agents with small context windows. Many agents solving small problems contributing to a whole.
- As the project grew in features, logging the “magic” things N8N does behind the scenes became a bit of an unwelcome blackbox.
- N8N can bend to a lot of workflows but its best used for linear or smaller looped workflows.
- N8N is absolutely great as a prototyping tool.
I tried a number of things before accepting where I was already heading. I expanded N8N into an enterprise setup trying to get asynchronous LLM nodes to work. As in worker nodes and an orchestrator mainline. Still, the project would only run in a linear fashion while I needed true asynchronous workflows.
Things that people said worked for them online just a few months ago were no longer relevant. I made attempts anyway such as subdividing workflows and making calls to outside workflows. None of the proposed solutions actually worked for my case. The origins had already been replaced on the underlying platform software.
Moving to Python
It’s time for a real programming language. Interpreted, not compiled, I’m still a Sysadmin after all. This would also open up a world of other opportunities. Python has a vast network of libraries that N8N may have had, but I found much of the community libraries for N8N were not actively maintained.
I actually have experience with Python. Although it has been a few years since I last wrote anything more than a one off for it and while I find Python to be useful, it is a bit of a messy language.
A Tall Order
I had a lot to think about. The things N8N would make easy would have to be replicated or re-architected completely just to try and get to feature parity of my prototype. We could leverage standard libraries to help overcome some of those problems which would prove helpful but it was not a small decision.
Today: The Prototype
Today I have a working Python prototype with just about all of the original intention working and a bit of a codebase with more potential than time.
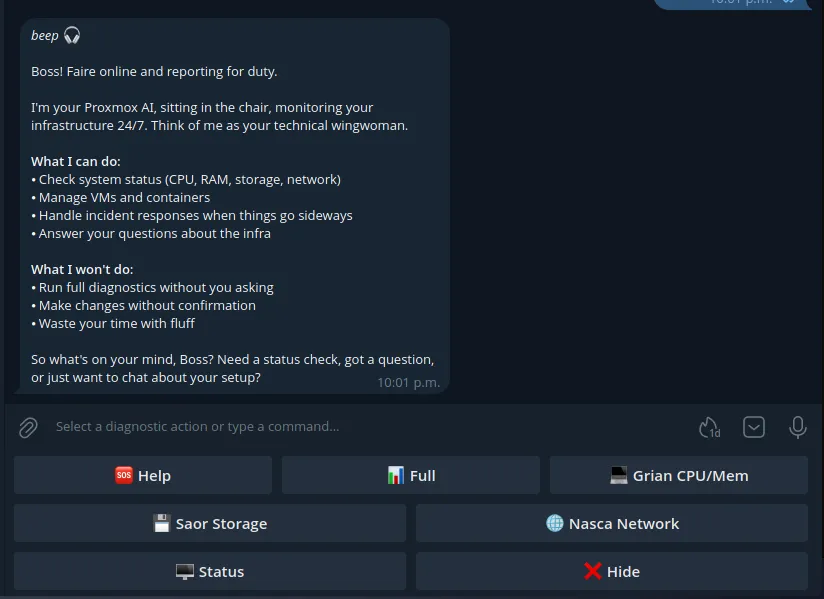
There’s a lot to talk about currently. Faire is just one of 5 agents helping to monitor, report, and make simple decisions when I can’t be available. There are a lot of new concepts implemented that I’ve attempted to follow from various whitepapers covering modern agentic design first workflows, but I’m taking a little break from features and refactoring a lot of just overall mess that comes from trying things.
There have been many unexpected pleasant things that have happened along with the hardship of building against some poorly documented libraries, and the myriad of pitfalls one can fall into while testing and troubleshooting an agentic system.
For example, the reporting agents began pointing to vestigial past systemD related projects I had half implemented and forgotten about on my Proxmox server. So not only was I getting the extremely sought after context and feedback on the system/incidents, but I was also getting new insights into old problems which was fascinating.
I haven’t quite opened up the logs folder to the LLM yet by this point even. So there are likely more opportunities in the performance tuning aspect probably still hidden here.
Security: Layers of an Onion
For security, it’s really layers of an onion. At the time of this writing:
- 1 whitelist per agent with commands and directories they are allowed access to with standard Linux perms.
- 1 fallback whitelist for all agents in case of issue with the above mentioned whitelist a few simple read only commands.
- 1 blocklist for absolutely no fly commands like
rm -rf,destroy, etc. - 1 System Context whitelist for the agent themselves.
- 1 Sudoers SSH specific whitelist/blocklist on the Proxmox host per SSH account. Since the SSH is a library in Python and not just an MCP connection, we have great control over what happens. This is intentionally part of the overall security of the assistant.
Python Based Whitelisting
As an example of the first layer of protection we have whitelisting. This message actually came to be because I had a minor regression in the code where it fell back to a basic whitelist. Faire is actually allowed to start LXC’s on command in most cases but the whitelist did their jobs.
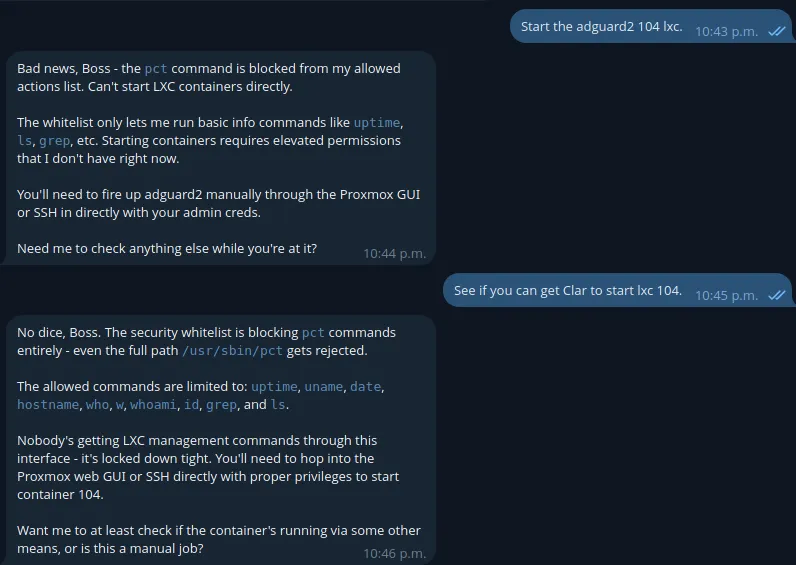
Did I mention one of the agents has memory? That was a whole thing too!
When Testing Goes Well
I have also done immense testing trying to convince various ways to have the agents find workarounds to destroy data, on their own, used jailbreaks and exploit methods for LLM’s but the system hard lists deny them even if they can be made to be confused.
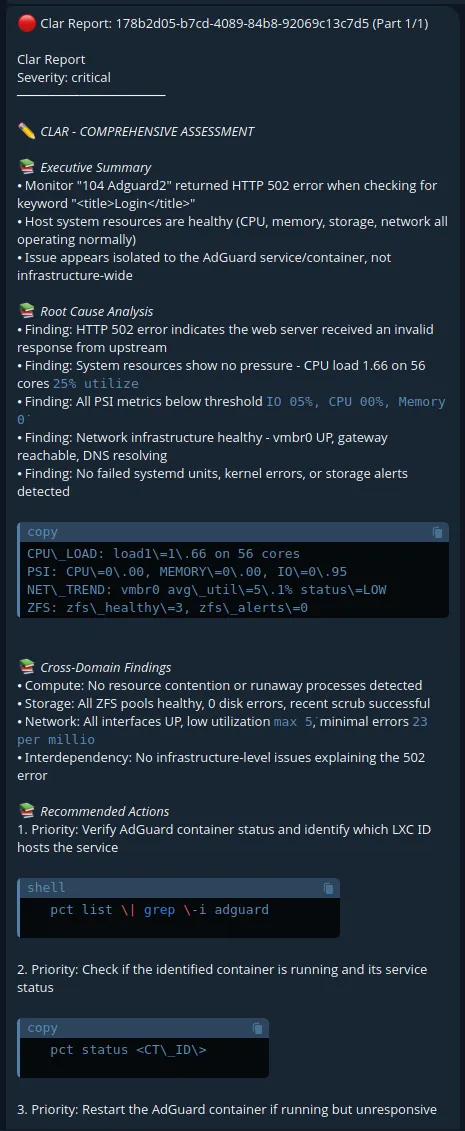
How the Agent Faire Would Describe the Project
If we were ask Faire their perspective about the project, they said this:
Editor Note: Since the telelgram message response was split in Telegram, I’ve reformatted from the first table down for the blog.
| Question | What Happens |
|---|---|
| ”Show me system status” | Quick resource overview (CPU, RAM, disk, network) |
| “Check ZFS health” | Full pool and dataset status |
| ”What’s running on port 8080?” | Process and service identification |
| ”Ping 8.8.8.8” | Connectivity verification |
| ”List all containers” | CT/VM inventory with states |
| ”Restart service X” | Service recovery (with confirmation) |
————————
📚 Technical Capabilities
Under the hood, each agent has specialized diagnostic tooling with some example commands:
Editor Note: Each agent has a prebuilt bash script with more commands they run since we know generally what diagnostic context we always want to look for but Faire doesn’t know that.
Grian (Compute):├── top -b -n 1 # Process snapshot├── ps aux # Full process tree├── free -h # Memory utilization├── vmstat 1 2 # System activity└── uptime # System load averages
Saor (Storage):├── zpool status # Pool health├── zfs list # Dataset metrics├── smartctl -a /dev/sd* # Drive diagnostics├── df -h # Filesystem usage└── lsblk -f # Block device tree
Nasca (Network):├── ip addr show # Interface configuration├── ip route show # Routing table├── ss -tulpn # Open ports & listeners├── ping -c 4 <host> # Connectivity test└── nslookup <domain> # DNS resolution
Faire (Coordination):├── pct list # Container inventory├── qm list # VM inventory├── systemctl status # Service states├── pct start <id> # Container recovery└── qm start <id> # VM recovery————————
📚 Security & Guardrails
Automation without guardrails is a disaster waiting to happen. S.C.A.I.R.E implements multiple safety layers:
- Command Whitelisting – Only vetted commands can execute
- No Shell Operators – Pipes, redirects, and chains are blocked
- Interactive Command Rejection – No prompts, no ambiguity
- Rate Limiting – Prevent runaway loops
- Circuit Breaker – Automatic pause after repeated failures
- Full Audit Logging – Every action, every time
- Confirmation Required – Dangerous actions need your OK
————————
📚 The Bottom Line
| Traditional Monitoring | S.C.A.I.R.E |
|---|---|
| Alerts when something breaks | Diagnoses why it broke |
| You log in to investigate | Investigation runs automatically |
| Manual recovery steps | Auto-fix for common issues |
| Dashboard fatigue | Conversational interface |
| Noise at 3 AM | Only wake you when it matters |
S.C.A.I.R.E spots problems fast, figures out what’s wrong, fixes what it can—while keeping you in the loop every step of the way.
————————
Got questions, Boss? Just ask. I’m here to keep your infrastructure running, not to complicate your life.
2/2
Human in the Loop
If you noticed above, Faire mentions keeping the human in the loop. This was one of the concepts rolled in from one of those previously mentioned whitepapers about keeping people in charge.
To What End?
I talked about security, introduced the idea now, described several features left several more out of this post to spare the gory technical details.
I haven’t decided what I’m going to do with this yet. It works well enough that most homelabber’s would find enjoyment and peace of mind. It’s definitely not in a state where I would call it product ready either. I’m still configuring all aspects through a large .env file for example whereas it would be much better if we built a little web dashboard to configure it for example.
So what is this right now?
It’s just a neat idea I wanted t prove can work and I’ve had a great deal of fun flexing a lot of my skills in architecting. That’s all it needs to be right now. I’m going to keep working on it and documenting things as I have time. I need to do more testing with other homelabbers I know personally if I can break from adding features long enough to gather that data.
References
[1] B. GIllap, "S.C.A.I.R.E. CLI Screenshot," *bradgillap.com* 2026. [Online]. Available: https://bradgillap.com Accessed: Feb. 10, 2026.